 Hangga Aji Sayekti
Hangga Aji Sayekti 
Sekilas tentang OCR
Optical Character Recognition atau disingkat menjadi OCR adalah sebuah proses pengenalan atau pememindaian karakter secara optical. Atau boleh dibilang OCR ini merupakan rekayasa teknologi yang mampu mengenali teks dari sebuah gambar seperti foto, hasil scan dokumen.
Sehingga teknologi OCR ini bisa menjawab kebutuhan pemindaian dan penyalinan teks dalam waktu singkat. Kalau anda sering memindai/scan dokumen, software dan aplikasi OCR bisa mempersingkat waktu untuk mengedit berkas yang tidak memiliki soft copy.
Diantara manfaat OCR antara lain
– Data entry secara otomatis.
– Menyalin/mengedit atau mencontek(ha3x) buku hasil scan
– Mengkonversi tulisan tangan ke dokumen digital.
– Membuat dokumen tulis tangan agar bisa di-index
– Dan masih banyak lagi.
Teknologi Lawas
Sebenarnya OCR ini adalah teknologi lawas a.k.a sudah ditemukan sejak lama. Tahun 1914 ilmuwan Emanuel Goldberg sudah mampu membuat mesin yang mampu mengubah karakter tercetak ke dalam kode standard telegraf. Kemudian Edmund Fourier mengembangkan Optophone yang merupakan mesin pemindai jinjing yang mampu menghasilkan bunyi sesuai dengan karakter khusus yang tercetak di dokumen.
Baru pada dekade 1990an, OCR banyak dimanfaatkan oleh perpustakaan-perpustakaan untuk mendigitalkan surat kabar bersejarah. Proyek digitalisasi buku-buku bersejarah dan sumber referensi primer ini mulai menjamur memasuki abad 21 karena didukung oleh perkembangan pesat di bidang perangkat keras, perangkat lunak dan Internet.
Proses OCR
Adapun proses OCR ini umumnya ada 4 tahap.
- Extraction of Character boundaries from Image,
- Building a Convolutional Neural Network(ConvNet) in remembering the Character images,
- Loading trained Convolutional Neural Network(ConvNet) Model,
- Consolidating ConvNet predictions of characters.
Menggunakan library/ API
Cara termudah dalam membuat aplikasi OCR adalah dengan menggunakan API atau library. Dengan cara ini kita tidak perlu pusing membuat algoritmanya karena sudah dilakukan oleh API atau library. He3x enak kan. Diantara contoh yang saya tahu adalah Tesseract dan Google Vision.
Google Vision untuk Android
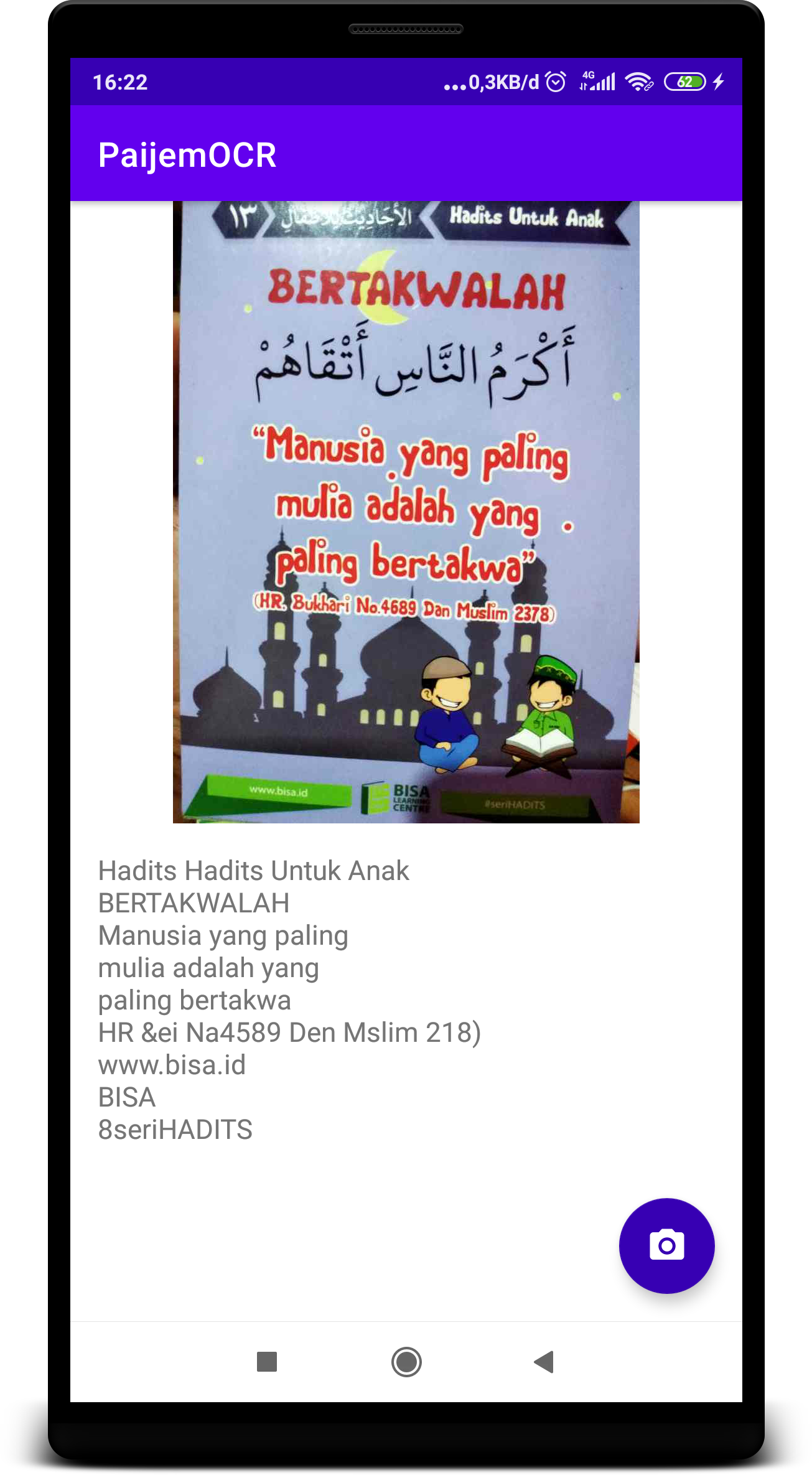
Seperti biasa, buka gradle lalu tambahkan pada dependency
implementation 'com.google.android.gms:play-services-vision:11.8.0'
Kita buat attach camera, kemudian convert menjadi bitmap.
Kemudian kita perlu mencreate instance sebuah frame dengan image data berupa bitmap tersebut. Kemudian frame ini nanti akan didetect oleh TextRecognizer milik Google Vision lalu hasilnya ditampung dalam StringBuilder.
Sederhana sekali bukan.
Main logicnya ada disini:
private void goProcess() {
TextRecognizer txtRecognizer = new TextRecognizer.Builder(getApplicationContext()).build();
if (!txtRecognizer.isOperational()) {
txtView.setText(R.string.error_prompt);
} else {
Frame frame = new Frame.Builder().setBitmap(bitmap).build();
SparseArray items = txtRecognizer.detect(frame);
StringBuilder strBuilder = new StringBuilder();
for (int i = 0; i < items.size(); i++) {
TextBlock item = (TextBlock) items.valueAt(i);
strBuilder.append(item.getValue());
strBuilder.append("\n");
}
txtView.setText(strBuilder.toString().substring(0, strBuilder.toString().length() - 1));
}
}
Atau mau langsun coba di Android Studio bisa checkout disini
https://github.com/hangga/PaijemOCR
Referensi:
https://mti.binus.ac.id/2017/07/03/optical-character-recognition-ocr/
https://review.bukalapak.com/techno/mengenal-teknologi-ocr-bisa-mengekstrak-teks-dari-gambar-17503
https://id.wikipedia.org/wiki/Pengenalan_karakter_optis
https://medium.com/datadriveninvestor/4-simple-steps-in-building-ocr-1f41c66099c1
 Pengalaman Mengikuti Test Engineer Bukalapak 2020
Pengalaman Mengikuti Test Engineer Bukalapak 2020